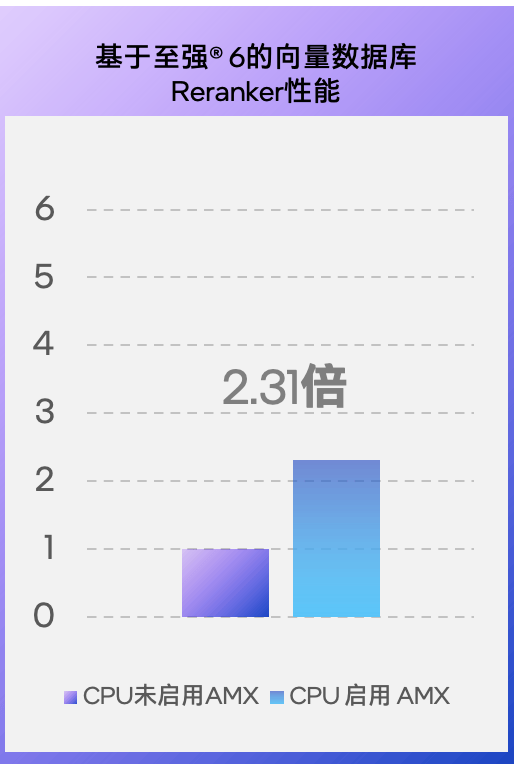
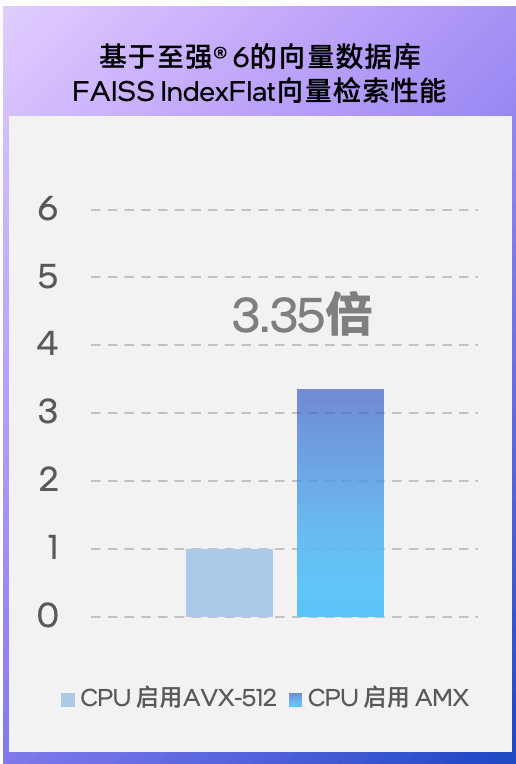
一直被当成 “GPU 小跟班” 的机头 CPU,早不是“GPU忙死我旁观、算力大活我不担“的角色了,尤其是至强处理器开启AMX技术的支持后——英特尔近期就在多个与客户及合作伙伴沟通的场合中披露了向量数据库上的多个测试数据,如:在至强6性能核处理器上,开启AMX进行加速后, FAISS IndexFlat向量检索性能提升达3.35倍,Reranker性能也会拉到未启用时的2.31倍。还有一组基于第五代至强可扩展处理器平台的测试数据:在激活AMX加速后,其上的向量数据库的Embedding性能也可拉到未开启时的4.79 倍。所有这些基于实战的数据都指向一点:至强CPU能帮 GPU分担向量数据库的工作。

如果你问这有啥意义?我就得反问你:让CPU把数据预处理的“杂活”干好,让GPU更专注高价值的AI训练或推理加速,这难道不香么?
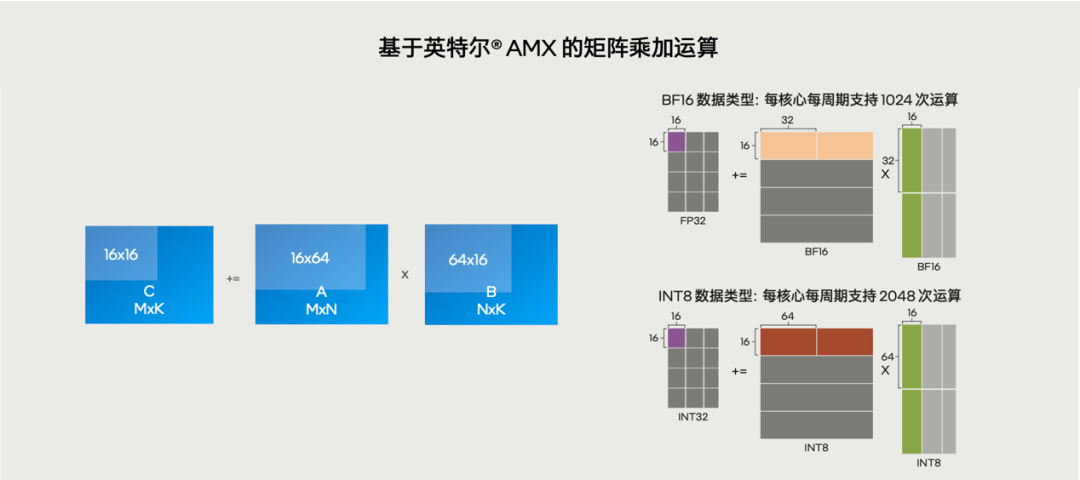
要是第四代之前的至强CPU,这种高度依赖矩阵计算能力的“杂活”它还真不太容易扛,但自从2023年开始内置了AMX(高级矩阵扩展)技术后,它还真就从从容容,游刃有余了!有人曾戏称AMX是“CPU里的 Tensor Core”,就是因为它天生就是为矩阵运算加速而设计的。
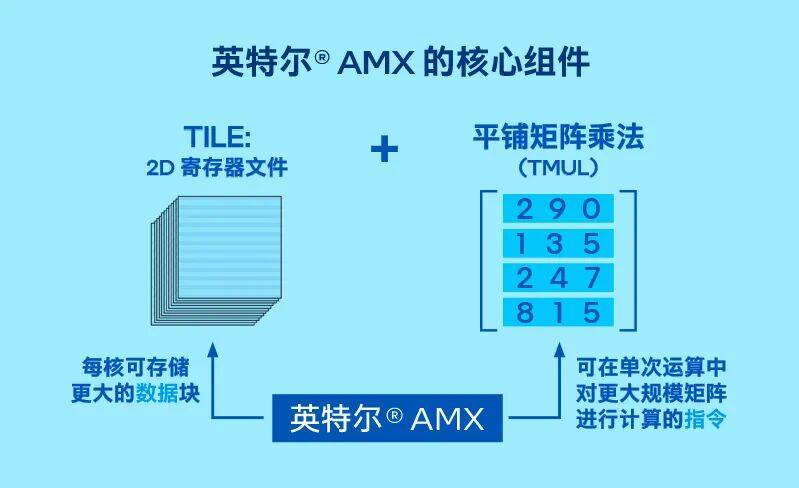
8 个 1KB 二维 TILE 寄存器组成高速缓存区,能少跑好多内存访问的冤枉路;TMUL 乘法单元一次能处理 16×16 矩阵块,再加上 INT8、BF16和FP16低精度支持,每核心每时钟周期能完成 2048 次操作,是传统 AVX-512 技术的 8 倍。
这些能力不是要抢GPU 风头,而是要帮 GPU 卸包袱:各种数据预处理,特别是向量数据库的杂活 CPU 接了,GPU 才能专心干大事,让花在它身上的每分钱都更物有所值。
这里就要先说说数据预处理——这是AI工作的“前置准备”阶段,以前常要 GPU 分心兼顾。AI 工作负载里的非结构化数据解析、格式转换、特征清洗,看着是“细活”,实则要高并行逻辑和高 I/O 吞吐,正好是机头CPU的强项。更重要的是:CPU 把预处理扛了,GPU 就不用在训练推理这样的核心任务和预处理这种边缘任务之间来回切换,算力与时间一点儿都不浪费。
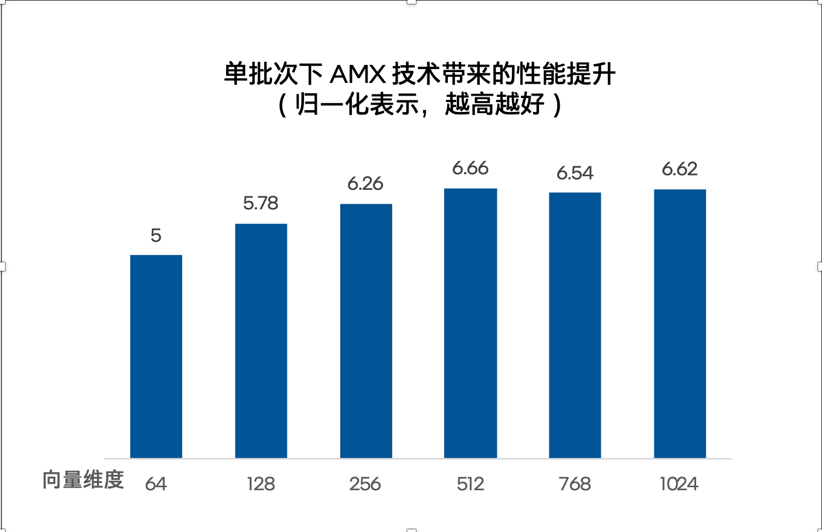
对于向量数据库,有AMX加成的至强则把 “帮 GPU 分担” 做到了实处。向量存储、索引构建、相似度检索等流程,都由Embedding、相似度计算等组成,本质都是密集型矩阵运算 —— 这正是 AMX 的拿手戏。据英特尔曾经公布的更多的测试结果:在 FAISS 库测试里,1,000 万级向量数据集,AMX 的加成让单批次查询速度快 5 到 6.66 倍。1
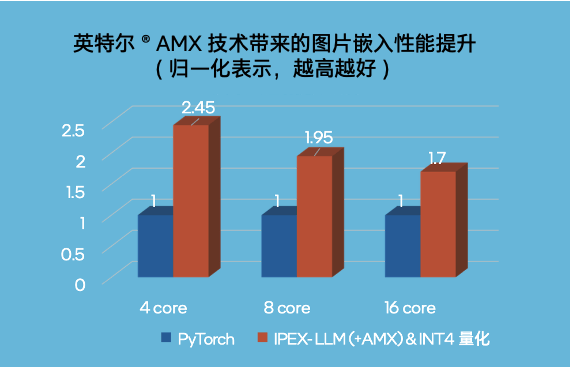
图片嵌入场景下,4 核至强实例性能涨到 2.45 倍,16 核实例也能提升达 1.7 倍。2
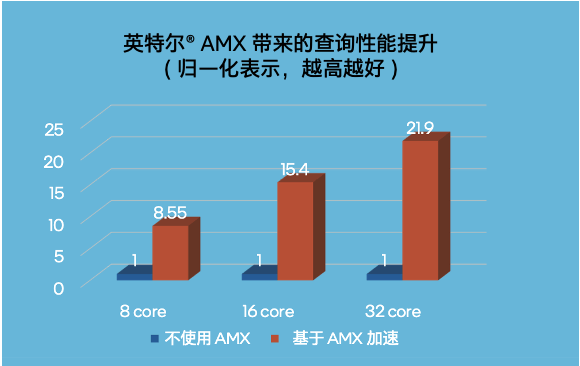
最关键的 50 万条记录检索,32 核至强直接把速度提到 21.9 倍。3这些活儿要是扔给GPU,不光检索慢,还得挤占推理算力,整体效率得打对折。
这套 “至强分担跑向量数据库 + GPU 专注做训练与推理” 的分工机制,直接改写了 AI 部署的性价比。传统方案里,GPU 又做预处理又跑AI算力密集型任务,就像 “一人干两份活”,吞吐量上不去还容易卡壳;现在至强把向量数据库的活接稳了,AI 集群整体吞吐量提升的基础上,GPU 应用的投资回报还能再上层楼。
另外,基于“至强+ AMX” 的机头系统在AI推理上展现出的更优性价比,有越来越多的用户受到启发,开始将AI模型预处理、小参数LLM推理交给机头CPU来执行。相对的,GPU则能解放生产力,更专注做高价值的任务,算下来每一分算力都花在刀刃上。
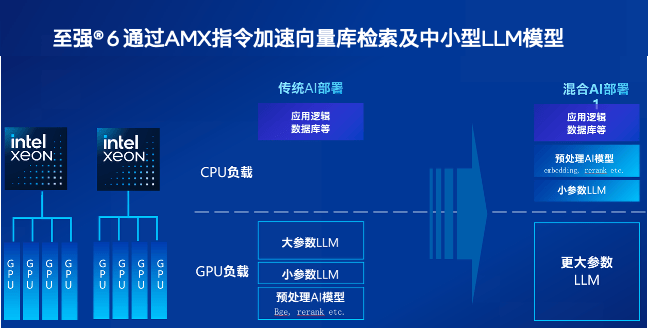
所以别再让你的至强 CPU在AI服务器中“发呆”了,用好它,让它真正做好协同的工作,能让整个 AI 流程跑得更快、更省、投资回报更丰厚。所谓:不能帮 GPU 加速向量数据库的 CPU,真算不上好至强。接下来随着 AMX 支持更多数据类型、至强兼容高带宽内存,相信这种 “协同力” 还会更强。

















































































































![[快讯]和远气体97万限售股12月30日解禁](http://www.dianxian.net/uploadfile2022/0610/20220610021935495.jpg)

